파이썬 python/파이썬 기초 basic
NumPy
ynzify
2023. 5. 23. 01:07
벡터 (Vector)
- 1차원 데이터(1차원 배열)
- 스칼라(scalar)가 연속적으로 여러 개 모여 있는 것
>>> lst = [1,2,3,4,5,6]
>>> arr = np.array(lst)
>>> arr
array([1, 2, 3, 4, 5, 6])
행렬 (Matrix)
- 2차원 데이터(2차원 배열)
- 1차원 배열인 벡터가 여러 개 모여 있는 것
>>> lst = [
>>> [1,2,3],
>>> [4,5,6]
>>> ]
>>> arr = np.array(lst)
>>> arr
array([[1, 2, 3],
[4, 5, 6]])
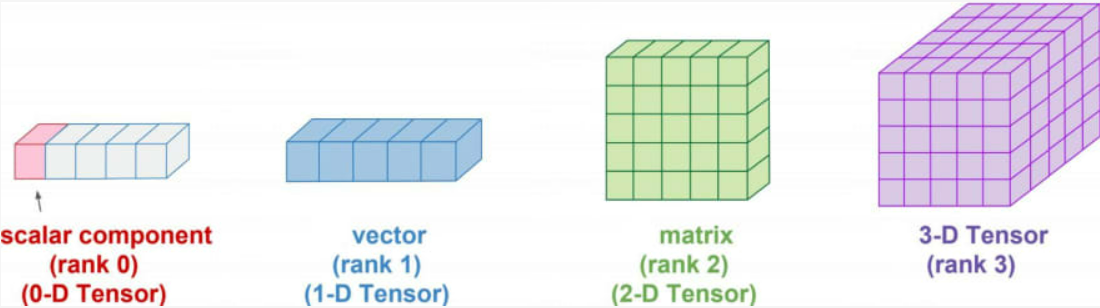
NumPy (Numerical Python)
- 수치계산을 위한 파이썬 라이브러리
- 딥러닝에서 사용되는 텐서와 매우 유사
- 벡터, 행렬 단위에 대용량 수치연산을 빠르게 해줌
- 다차원 배열(array)을 다룰 때 사용
pip install numpy
import numpy as np
3차원 배열을 만들어 보자
>>> lst = [
>>> [
>>> [1,2,3],
>>> [4,5,6]
>>> ],
>>> [
>>> [7,8,9],
>>> [10,11,12]
>>> ]
>>> ]
>>> arr = np.array(lst)
>>> arr
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
NumPy의 배열 (ndarray)
- 배열의 타입을 ndarray라 한다
- 배열은 동일한 타입의 값을 가진다
속성
- ndim: 배열의 차원 수
- shape: 각 차원의 크기를 tuple로 표시한 것
- size: 배열 요소의 총 갯수
- dtype: 배열 안 요소의 데이터 타입
# 몇차원인가?
>>> arr.ndim
3
>>> arr.shape
(2, 2, 3)
# 총 갯수?
>>> arr.size
12
>>> arr.dtype
dtype('int32")
빈출 데이터 타입
데이터 타입 전부 알고 싶으면 딴 블로그 가셈
- 정수형 (int_)
>>> lst = [1,2,3]
# 4 바이트 크기의 정수 (기본값이어서 int32출력 안댐!)
>>> np.array(lst,dtype=np.int32)
array([1, 2, 3])
# 8 바이트 크기의 정수
>>> np.array(lst,dtype=np.int64)
array([1, 2, 3], dtype=int64)
# 1 바이트 크기의 부호 없는 정수
>>> np.array(lst,dtype=np.uint8)
array([1, 2, 3], dtype=uint8)
- 실수형 (float_)
# 8 바이트 크기의 실수 (float64가 기본 값)
>>> np.array(lst,dtype=np.float64)
array([1., 2., 3.])
# 4 바이트 크기의 실수
>>> np.array(lst,dtype=np.float64)
array([1., 2., 3.], dtype=float32)- 논리형
>>> np.array([1,0,1],dtype=np.bool_)
array([ True, False, True])
배열 만들기
- 리스트 사용
>>> lst = [
>>> [
>>> [1,2,3],
>>> [4,5,6]
>>> ]]
#리스트 만들어서 array함수 안에 넣어주기
>>> arr = np.array(lst)
>>> print(arr)
>>> print(arr.shape)
[[[1 2 3]
[4 5 6]]]
(1, 2, 3)
- 함수 사용
- 종류
| arange() | ndarray를 반환 |
| zeros() | 0으로 채워진 배열을 반환 |
| ones() | 1으로 채워진 배열을 반환 |
| full() | 지정값으로 채워진 배열을 반환 |
| eye() | 대각선으로 1 대입, 나머지는 0을 대입하는 2차원 함수 |
| reshape() | 다차원으로 변형하는 함수 |
# arange() 열개 정수의 배열을 반환
>>> np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.arange(1,10,2)
array([1, 3, 5, 7, 9])
# zeros()
>>> np.zeros(10)
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
>>> np.zeros([6,1])
array([[0.],
[0.],
[0.],
[0.],
[0.],
[0.]])
# np.ones
>>> np.ones(10)
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
>>> np.ones([2,3,4])
array([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
# np.full
>>> np.full([3,5],True)
array([[ True, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True]])
다차원 슬라이싱
>>> arr = np.array([
>>> [1,2,3],
>>> [4,5,6],
>>> [7,8,9],
>>> [10,11,12]
>>> ])
>>> arr
>>> arr.shape
(4,3)
>>> print(arr)
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
# 1번 열만 가져오고 싶다면?
>>> arr[:,0]
array([ 1, 4, 7, 10])
>>> arr[:,::2] / arr[:,0:3:2]
array([[ 1, 3],
[ 4, 6],
[ 7, 9],
[10, 12]])
# 2, 5, 9, 12 가져오기
>>> arr[:2:1,1::]
array([[2, 3],
[5, 6]])
# 행(두칸씩 띄기),열(두칸씩 띄기)
>>> arr[::2,::2]
array([[1, 3],
[7, 9]])
# 0번 열과 2번열을 가져오고 싶다면?
>>> arr[:,::2]
array([[ 1, 3],
[ 4, 6],
[ 7, 9],
[10, 12]])
>>> arr[::2]
array([[1, 2, 3],
[7, 8, 9]])
>>> arr[:,1:]
array([[ 2, 3],
[ 5, 6],
[ 8, 9],
[11, 12]])
>>> arr[::2,::2]
array([[1, 3],
[7, 9]])
마스킹 (masking)
- bool 배열을 마스크로 해서 데이터의 특정 부분만 선택해서 가져옴
>>> arr
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
# mask = [True,False,True,False]
>>> mask = np.array([True,False,True,False])
>>> arr[mask]
array([[1, 2, 3],
[7, 8, 9]])
# 열 부분 마스킹을 하고 싶다면?
>>> mask = np.array([True,False,True])
>>> arr[:,mask]
array([[ 1, 3],
[ 4, 6],
[ 7, 9],
[10, 12]])
# >>> arr[:mask] 이런거 저런거 해봤는데 차원 안 맞는다고 다 에러뜸!!!
# 모든 스칼라에 대해 마스킹을 한다면 벡터로 반환
>>> mask = arr > 2
>>> arr[mask]
array([ 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
# 다수의 인덱스 값들을 이용해 선택
>>> index_list = [0,2]
>>> arr[index_list]
array([[1, 2, 3],
[7, 8, 9]])
>>> arr[:,index_list]
array([[ 1, 3],
[ 4, 6],
[ 7, 9],
[10, 12]])
행렬곱
- 2차원 공간에서 내적
- 앞에 행렬의 열개수, 뒤에 행렬의 행개수가 동일해야 함
- 결과 행렬의 크기: 앞에 행렬의 행개수, 뒤에 행렬의 열개수
>>> arr1 = np.array([
>>> [1,2,3],
>>> [4,5,6],
>>> [7,8,9]
>>> ])
>>> arr2 = np.array([
>>> [0,1],
>>> [0,1],
>>> [0,1]
>>> ])
>>> arr1.shape, arr2.shape
((3, 3), (3, 2))
# 행렬곱
>>> arr1 @ arr2
array([[ 0, 6],
[ 0, 15],
[ 0, 24]])NumPy 함수
배열의 요소별 연산 (element-wise)
>>> arr1 = np.array([1,2,3])
>>> arr2 = np.array([3,2,7])
# arr1 + arr2
>>> np.add(arr1,arr2)
array([ 4, 4, 10])
# arr1 - arr2
>>> np.subtract(arr1,arr2)
>>> arr1 - arr2
array([-2, 0, -4])
# arr1 * arr2
>>> np.multiply(arr1,arr2)
array([ 3, 4, 21])
# arr1 / arr2
>>> np.divide(arr1,arr2)
array([0.33333333, 1. , 0.42857143])
# 절대값
>>> np.abs(arr1 - arr2)
array([2, 0, 4])
- 브로드캐스팅 (broadcasting)
- 배열의 모양이 다르더라도 어떤 조건이 만족했을 때 연산이 가능해지도록 작은 배열을 큰 배열 크기로 맞춰는 것
>>> lst = [
>>> [1,2,3],
>>> [4,5,6],
>>> [7,8,9],
>>> [10,11,12]
>>> ]
>>> arr = np.array(lst)
>>> arr
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
- 스칼라일 경우 큰 배열 크기로 반환돼서 연산
>>> arr * 2
array([[ 2, 4, 6],
[ 8, 10, 12],
[14, 16, 18],
[20, 22, 24]])
- 열 크기를 맞추면 행이 늘어나 연산
>>> arr * np.array([2,1,0])
array([[ 2, 2, 0],
[ 8, 5, 0],
[14, 8, 0],
[20, 11, 0]])
- 행 크기를 맞추면 열이 늘어나 연산
>>> arr * np.array([
>>> [1],
>>> [2],
>>> [3],
>>> [4]
>>> ])
array([[ 1, 2, 3],
[ 8, 10, 12],
[21, 24, 27],
[40, 44, 48]])
- Norm (암기 해주기)

# L1 norm
>>> np.linalg.norm([-1,2,3],1)
6.0
# L2 norm
>>> np.linalg.norm([-1,2,3])
3.7416573867739413
- 내적 (dot product)
# 두 벡터의 각 요소끼리 곱의 합
>>> a = np.array([1,2,3])
>>> b = np.array([4,5,6])
# 결과 값은 스칼라
>>> np.dot(a,b)
>>> a @ b
32
집계 함수
>>> scores = np.array([80,90,100,70,40,90])
# 총합
>>> np.sum(scores) , scores.sum()
(470, 470)
# 평균
>>> np.mean(scores) , scores.mean()
(78.33333333333333, 78.33333333333333)
# 중앙값
>>> np.median(scores)
85.0
# 최댓값
>>> np.max(scores) , scores.max()
(100, 100)
# 최소값
>>> np.min(scores) , scores.min()
(40, 40)
# 최댓값의 인덱스를 반환
>>> np.argmax(scores) , scores.argmax()
(2, 2)
# 최솟값의 인덱스를 반환
np.argmin(scores) , scores.argmin()
(4, 4)
# 중복 제거
>>> arr = np.array([1,3,3,4,4,4,6,6,6,6,6,6,6])
>>> np.unique(arr)
array([1, 3, 4, 6])
# 제곱
>>> np.square([2,3,4])
array([ 4, 9, 16])
# 루트
>>> np.sqrt([2,3,4])
array([1.41421356, 1.73205081, 2. ])
# 반올림
>>> np.round([5.3,7.5,8.8])
array([5., 8., 9.])
>>> np.round([5.31,7.55,8.88],1)
array([5.3, 7.6, 8.9])
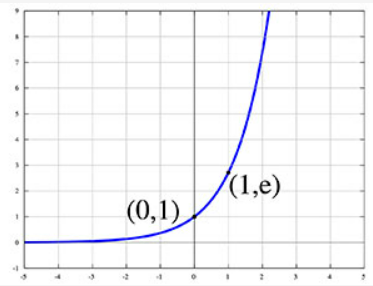
- exp 함수: y=e^x
- 자연상수 (2.71828)를 밑으로 하는 지수함수
- x 에 0이 들어가면 1이 반환, 1이 들어가면 자연상수가 반환
- x 값이 조금만 커져도 함수 값이 기하급수적으로 커짐
# infinite
>>> np.exp(1000)
inf
>>> float("inf")
inf
>>> np.exp(1)
2.718281828459045
>>> np.exp(0)
1.0
>>> np.exp([1, 2, 3, 4])
array([ 2.71828183, 7.3890561 , 20.08553692, 54.59815003])
- exp 함수: y = log_e x
- 자연상수 (e)를 밑으로 하는 로그함수
- x 에 0이 들어가면 음수 무한대, 1이 들어가면 0 반환

>>> np.log([0,1])
# 0이 들어갔으니까 infinite이 나온거임 1이 들어갔으니까 0이 나온거고!!
array([-inf, 0.])
>>> np.log(10000000000000)
29.933606208922594
- 분위수 구하기
- 데이터 크기 순서에 따른 위치값
- 이상치에 영향을 덜 받는다
- 0.5값을 줄 경우, 중앙값
>>> arr = np.array([100,3,3,6,7,9,20,10,9])
>>> np.quantile(arr,0.5) , np.median(arr) , np.mean(arr)
(9.0, 9.0, 18.555555555555557)
>>> np.quantile(arr,0.05)
3.0
>>> np.quantile(arr,[0,0.25,0.5,0.75,1])
array([ 3., 6., 9., 10., 100.])
- 정렬하기
# 오름차순
>>> np.sort(arr)
array([ 3, 3, 6, 7, 9, 9, 10, 20, 100])
# 내림차순
>>> np.sort(arr)[::-1]
array([100, 20, 10, 9, 9, 7, 6, 3, 3])
배열 조건 연산
>>> scores = np.array([80,90,100,70,40,60])
>>> mask = scores >= 80
>>> mask
array([ True, True, True, False, False, False])
# 마스킹
>>> scores[mask]
array([ 80, 90, 100])
# 요소 중에 조건의 참이 하나라도 있을 경우 True 반환
>>> np.any(scores >= 100)
True
# 모든 요소가 조건이 참일 경우 True 반환
>>> np.all(scores >= 40)
True
- np.where
- 첫번째 인수에 조건
- 두번째 인수에 참일 경우 채워 넣을 값
- 세번째 인수에는 거짓일 경우 채워 넣을 값
>>> np.where(scores >= 80, 1, 0)
array([1, 1, 1, 0, 0, 0])
>>> np.where(scores >= 80, scores, 0)
array([ 80, 90, 100, 0, 0, 0])
>>> arr = np.array([
>>> [1,2,3],
>>> [4,5,6],
>>> [-1,-1,2]
>>> ])
>>> np.where(arr > 0, 1, arr)
array([[ 1, 1, 1],
[ 1, 1, 1],
[-1, -1, 1]])
- np.clip
- 첫번째 인수로 배열
- 두번째 인수로 최솟값
- 세번째 인수로 최댓값
>>> np.clip(arr,0,5)
array([[1, 2, 3],
[4, 5, 5],
[0, 0, 2]])
- numpy 무한대값
>>> np.inf
inf
>>> -np.inf
-inf
- nan 값 (결측치)
>>> np.nan
nan
# 데이터 수집 혹은 전처리 과정에서 무한대 값과 결측치가 생겼다고 가정
>>> arr = np.array([np.inf,np.nan,4,5,7,8.1])
>>> arr
array([inf, nan, 4. , 5. , 7. , 8.1])
# 무한대 값 찾기
>>> np.isinf(arr)
array([ True, False, False, False, False, False])
# NaN 값 찾기
>>> np.isnan(arr)
array([False, True, False, False, False, False])
# 정상 데이터 찾기
>>> np.isfinite(arr)
array([False, False, True, True, True, True])
>>> mask = np.isfinite(arr)
>>> arr[mask == False] = 0
>>> arr
array([0. , 0. , 4. , 5. , 7. , 8.1])
numpy random
- rand 함수
- 0~1 사이에 랜덤한 값을 반환
# np.random.seed(42)
>>> np.random.rand()
0.9507143064099162
>>> np.random.rand(3)
array([0.73199394, 0.59865848, 0.15601864])
>>> np.random.rand(3,2,5)
array([[[0.15599452, 0.05808361, 0.86617615, 0.60111501, 0.70807258],
[0.02058449, 0.96990985, 0.83244264, 0.21233911, 0.18182497]],
[[0.18340451, 0.30424224, 0.52475643, 0.43194502, 0.29122914],
[0.61185289, 0.13949386, 0.29214465, 0.36636184, 0.45606998]],
[[0.78517596, 0.19967378, 0.51423444, 0.59241457, 0.04645041],
[0.60754485, 0.17052412, 0.06505159, 0.94888554, 0.96563203]]]
- randn 함수
- 평균 0이고 분산이 1인 정규분포의 랜덤값을 반환
>>> arr = np.random.randn(100, 10)
>>> arr.shape
(100, 10)
>>> arr.var() , arr.mean()
(0.9680259049763192, -0.008265771525470778)
- randint 함수
- start ~ end-1의 랜덤한 정수로 채워진 배열을 반환
- np.random.randint(start,end,shape)
>>> np.random.randint(50,100,[4,3])
array([[85, 67, 64],
[62, 68, 98],
[55, 97, 61],
[86, 66, 72]])
- shuffle 함수
- 반환값이 없고 인수로 넣은 배열 자체를 섞는다
>>> arr = np.arange(1,7)
>>> np.random.shuffle(arr)
>>> arr
array([6, 4, 3, 1, 5, 2])
>>> np.random.seed(99)
>>> arr = np.arange(1,7).reshape(3,2)
>>> np.random.shuffle(arr) # 행부분을 섞는다.
>>> arr
array([[1, 2],
[5, 6],
[3, 4]])
- choice 함수
- 지정한 개수만 랜덤하게 선택해 반환
# 복원 추출법
>>> np.random.choice(5,3)
array([3, 2, 2])
# 비복원 추출법
>>> np.random.choice(5,3,replace=False)
array([1, 0, 3])
# iterable 한 객체를 넣어도 됨
>>> np.random.choice(np.arange(10),3,replace=False)
array([2, 9, 3])
# 각 요소의 반환될 확률을 줄 수 있다. p 인수의 합은 1이 되야함
>>> np.random.choice(5,3,p=[1,0,0,0,0])
array([0, 0, 0])
>>> np.random.choice(5,3,p=[0.9,0.1,0,0,0])
array([0, 1, 0])
axis 이해하기
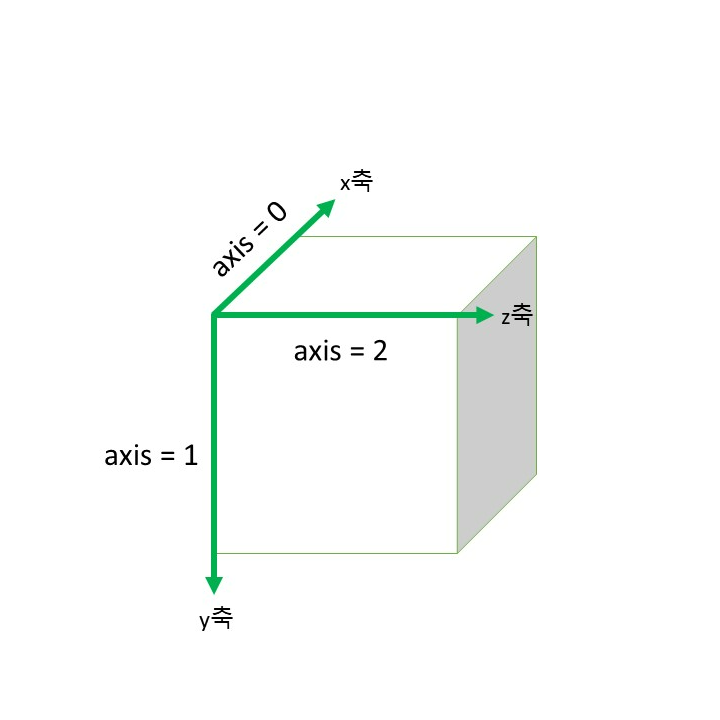
- axis = None : 기본값으로 모든 요소의 값을 합산하여 1개의 스칼라값을 반환
- axis = 0 : x축을 기준으로 여러 row를 한 개로 합치는 과정
- axis = 1 : y축을 기준으로 row 별로 존재하는 column들의 값을 합쳐 1개로 축소
- axis = 2 : z축을 기준으로 column의 depth가 가진 값을 축소
>>> np.random.seed(42)
>>> arr = np.random.randint(50,91,[4,3])
>>> arr
array([[88, 78, 64],
[57, 70, 88],
[68, 72, 60],
[60, 73, 85]])
np.random.seed(0)
난수를 발생시켜 수행한다
정해진 알고리즘에 따라 시작 숫자가 다르면 그에 따른 난수도 바뀜
그래서 random.seed를 붙이고 안붙이고의 결과값이 다른거!
>>> arr = np.random.randint(50,91,[4,3])
>>> arr
array([[89, 73, 52],
[71, 51, 73],
[79, 87, 51],
[70, 82, 61]])
>>> arr.sum(axis=0)
array([273, 293, 297])
>>> arr.sum(axis=1)
array([230, 215, 200, 218])
3차원 이상
>>> np.random.seed(42)
>>> arr = np.random.randint(50,91,[4,3,2])
>>> arr
array([[[88, 78],
[64, 57],
[70, 88]],
[[68, 72],
[60, 60],
[73, 85]],
[[89, 73],
[52, 71],
[51, 73]],
[[79, 87],
[51, 70],
[82, 61]]])
>>> arr.sum(axis=0)
array([[324, 310],
[227, 258],
[276, 307]])
# 4행 2열 (열방향으로 썸)
>>> arr.sum(axis=1)
array([[222, 223],
[201, 217],
[192, 217],
[212, 218]])
# 4행 3열 (행방향으로 썸)
>>> arr.sum(axis=2)
array([[166, 121, 158],
[140, 120, 158],
[162, 123, 124],
[166, 121, 143]])
배열 차원 추가 또는 변경하기
>>> arr = np.arange(6)
>>> arr
array([0, 1, 2, 3, 4, 5])
# 슬라이싱과 newaxis를 활용
>>> arr[:,np.newaxis]
array([[0],
[1],
[2],
[3],
[4],
[5]])
# axis 이용한 차원 추가 방법
>>> np.expand_dims(arr,axis=1)
array([[0],
[1],
[2],
[3],
[4],
[5]])
# reshape 이용한 차원 추가
# 행은 그대로 두고 1번째 차원에 추가하겠다
# 왜 행을 그대로 두는게 -1값인가?
>>> arr.reshape(-1,1)
array([[0],
[1],
[2],
[3],
[4],
[5]])
>>> arr2 = np.reshape(arr,[3,2])
>>> arr2
array([[0, 1],
[2, 3],
[4, 5]])
# 전치: 행이 열이되고 열이 행이 된다
>>> np.transpose(arr2)
array([[0, 2, 4],
[1, 3, 5]])
>>> arr2.transpose()
array([[0, 2, 4],
[1, 3, 5]])
>>> arr2.T
array([[0, 2, 4],
[1, 3, 5]])
>>> arr2.reshape(-1)
array([0, 1, 2, 3, 4, 5])
numpy 배열 합치기
- concatenate 함수
- axis 방향으로 배열 합치기
>>> arr1 = np.arange(1,7).reshape(3,2)
>>> arr1
array([[1, 2],
[3, 4],
[5, 6]])
>>> arr2 = np.array([
>>> [10,20]
>>> ])
>>> arr2.shape
(1, 2)
>>> np.concatenate([arr1,arr2],axis=0)
array([[ 1, 2],
[ 3, 4],
[ 5, 6],
[10, 20]])
# np.concatenate([arr1,arr2],axis=1): 옆으로 합칠때는 행갯수가 맞아야 함 에러 발생
>>> arr3 = np.array([
>>> [10],
>>> [20],
>>> [30]
>>> ])
>>> arr3.shape
(3, 1)
>>> np.concatenate([arr1,arr3],axis=1)
array([[ 1, 2, 10],
[ 3, 4, 20],
[ 5, 6, 30]])
- stack 함수
- 합치려는 배열들의 차원 크기가 모두 동일해야 함
- 합치려는 배열이 하나의 샘플로 취급
>>> arr1.shape, arr2.shape
((3, 2), (1, 2))
# np.stack([arr1,arr2],axis=1) # 행크기가 달라서 에러발생
>>> arr2 = np.arange(11,17).reshape(3,2)
>>> arr2.shape
(3, 2)
>>> np.stack([arr1,arr2]).shape
(2, 3, 2)
- ndarray를 리스트로 변경
>>> arr1.tolist()
[[1, 2], [3, 4], [5, 6]]
- ndarray 복사
- 깊은 복사 (deep copy)
>>> arr_back = arr1.copy()
ndarray 저장하고 불러오기
# npy 확장자 생략시 자동으로 .npy 가 붙음
>>> np.save("data/arr.npy",arr1)
>>> arr = np.load("data/arr.npy")
>>> arr
array([[1, 2],
[3, 4],
[5, 6]])