딥러닝
딥러닝 (Deep Learning) 개요
ynzify
2023. 7. 8. 17:02
인공신경망
- 소프트웨어적으로 인간의 뉴런 구조를 본떠 마든 기계학습 모델
- 인공지능을 구현하기 위한 기술 중 한 형태
- 뉴런을 모방하는 기초단위 노드 (Node)
- 각각의 신경 단위에서 많은 입력들을 조합해서 하나의 출력값으로 배출
- 비선형 변환(활성함수)을 통해 다음 노드에 전달
- 피드 포워드(Feed-Forward) 신경망
- 입력에서 출력으로 이어지는 과정이 한방향으로 흘러 순환이 없는 신경망

인공 뉴런 (퍼셉트론)
- w: weight (가중치)
- b: bias (편향)
- h(): activation funciton


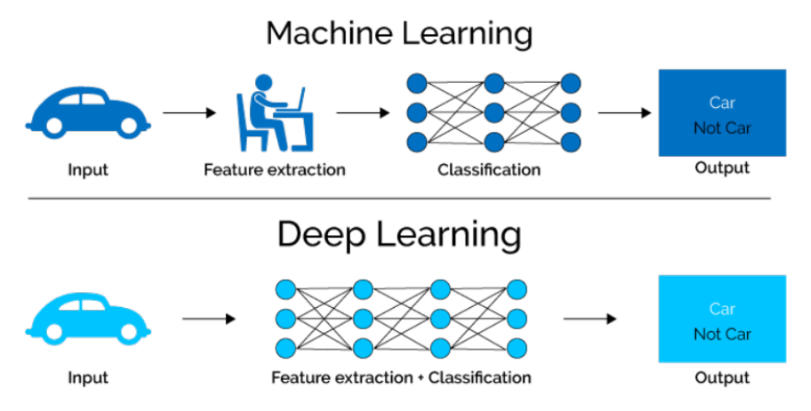
딥러닝 (Deep Learning)
- 딥러닝은 머신러닝 알고리즘 중 하나인 인공신경망을 다양하게 쌓은 것
- 인공신경망을 여러 겹으로 쌓으면 딥러닝이다
- 머신러닝이 처리하기 어려워하는 비정형 데이터를 더 잘 처리한다

딥러닝의 단점
- 학습을 위해 상당히 만은 양의 데이터를 필요로 함
- 계산이 복자바고 수행시간이 오래걸림
- 이론적 기반이 없어 결과에 대한 장담이 어려움
- 블랙 박스 접근 방식

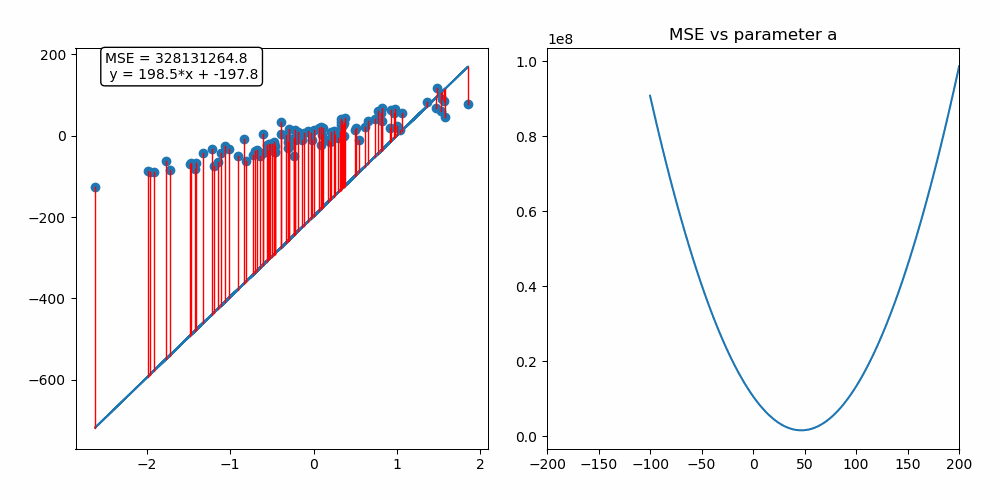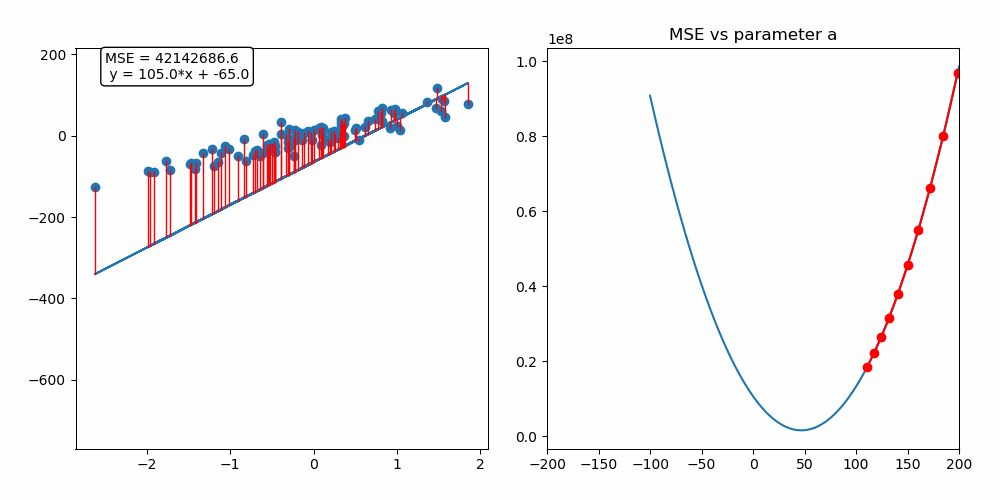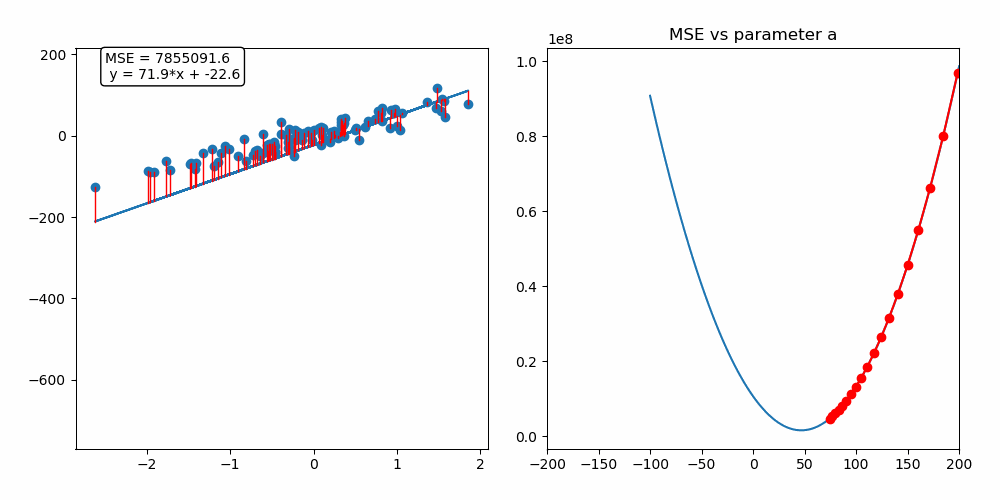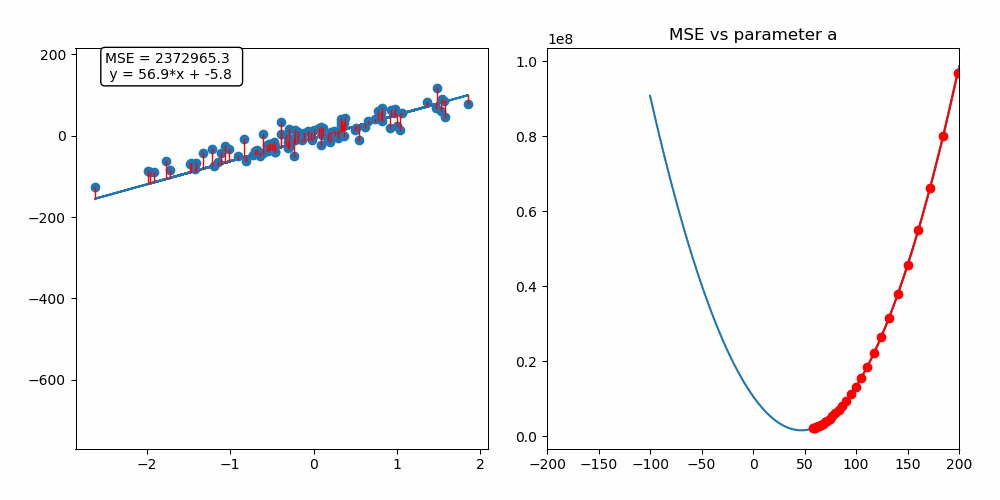
경사 하강법 (Gradient Descent)
- 모델이 잘 학습할 수 있도록 기울기(변화율)을 사용하여 모델의 파라미터를 조정하는 방법
- 과정
- 예측과 실제값을 비교하여 손실을 구함
- 손실이 작아지는 방향으로 파라미터 수정
- 반복
- 경사(기울기) - 파라미터에 대한 오차의 변화
- 기울기 +: 파라미터 ↓
- 기울기 - : 파라미터 ↑
- 과정
매개변수(媒介變數), 파라미터(parameter), 모수(母數)
수학과 통계학에서 어떠한 시스템이나 함수의 특정한 성질을 나타내는 변수를 말함
학습률 (Learning Rate)
파라미터를 업데이트 하는 정도를 조절하기 위한 값
- 학습률이 너무 큰 경우

- 학습률이 너무 작은 경우

순전파 (Forward Propagation)
- forward pass
- 입력 데이터를 기반으로 신경망을 따라 입력층(Input Layer)부터 출력층(Output Layer)까지 각 뉴런들이 자신만의 출력을 하는 과정


역전파 (Back-propagation)
- backward pass
- 효율적인 계산을 위해 역전파 알고리즘 사용
- 딥러닝은 역전파 알고리즘을 이용해 모든 가중치를 구함
- 손실값을 구해 이 손실에 관여하는 가중치들을 손실이 작아지는 방향으로 수정하는 알고리즘
- 파라미터를 업데이트할 때 필요한 손실에 대한 기울기를 역방향으로 업데이트
- 쉽게 역순으로, 거꾸로 곱해준다고 생각하기

기울기 소실 문제와 활성화 함수
- 층이 깊어지면서 역전파 과정에서 가중치를 수정하려는 기울기가 중간에 0이 되거나 0에 매우 가깝게 작아지는 경사 소실(vanishing gradient) 문제가 발생한다
기울기 소실(Vanishing Gradient)
- 딥러닝이 복잡해 질수록 기울기 소실이 발생


예시


해결 방법 -> ReLU

ReLU(Rectified Linear Unit) 함수
- 입력값이 음수이면 0을 출력하고 양수 값이면 그대로 흘려보내는 활성화 함수
- Sigmoid 함수의 기울기 소실 문제를 해결해준 함수 (시그모이드보다 효율적)
- 연산이 간편하고 Layer를 깊게 쌓을 수 있다는 장점
- 모든 뉴런을 전부 동시에 활성화 시키지 않는다
손실 함수 (Loss function)
- 모델의 출력값(output)과 정답과의 차이(오차 error)를 의미
- 신경망이 학습할 수 있도록 해주는 지표
- 손실 값이 최소화 되도록 하는 가중치(weight)와 편향(bias)를 찾는 것이 학습 목표
회귀(Regression)에서의 손실함수
- MSE (Mean Squared Error)
- L2 loss
- 이상치에 민감
- MAE (Mean Absolute Error)
- L1 loss
- 이상치에 강건

다중 분류(Multi-class Classification)에서의 손실 함수
- CE(Cross Entropy)
- 예측 확률이 실제값과 얼마나 비슷한가를 측정

이진 분류(Multi-class Classification)에서의 손실 함수
- BCE(Binary Cross Entropy)
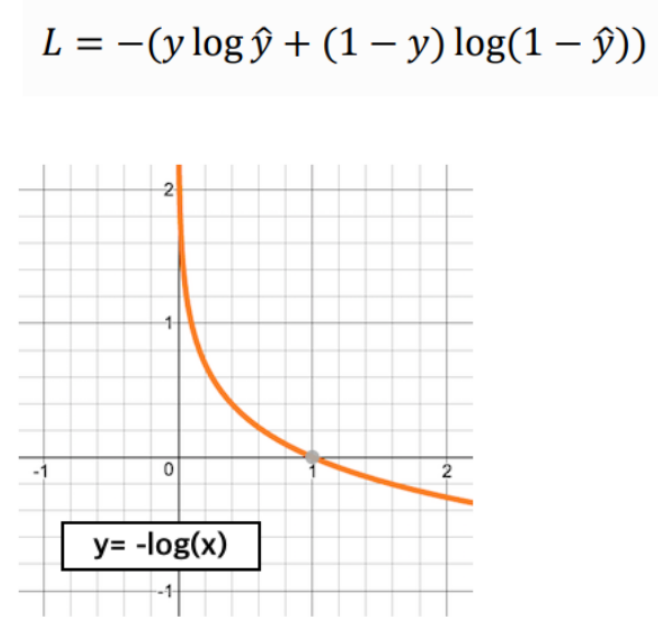
배치(Batch)
- 일을 모아서 한번에 처리하는 단위
- Batch Gradient Descent
- 장점: 전체 데이터에 대해 error gradient를 계산하기 때문에 optimal로 수렴이 안정적
- 단점: local optimal 상태가 되면 빠져나오기 힘듦
- Stochastic Gradient Descent
- 장점: shooting이 일어나기 때문에 local optimal에 빠질 위험이 적음
- 단점:global optimal을 찾지 못 할 가능성이 있다
- Mini-Batch Gradient Descent (요즘 사용중)
- 장점: BGD보다 local optimal에 빠질 리스크가 적다. (그래도 빠질 리스크는 있다)
- 단점: batch size(mini-batch size)를 설정해야 함

Optimizer
미니배치 경사 하강법의 방식을 보완하고, 학습 속도를 높이기 위한 알고리즘
- SGD(확률적 경사 하강법)
- 랜덤하게 추출한 일부 데이터를 사용해 더 빨리 업데이트 하게 하는 것
- 효과: 속도 개선
- Momentum
- 기존 업데이트에 사용했던 경사의 일정 비율을 남겨서 현재의 경사와 더하여 업데이트 함
- 효과: 정확도 개선
- Adagrad
- 각 파라미터의 update 정도에 따라 학습률의 크기를 다르게 해줌
- 효과: 보폭 크기 개선
- RMSProp
- Adagradd의 경우 update가 지속됨에 따라 학습률이 점점 0에 가까워지는 문제 발생
- 이전 update 맥락을 보면서 학습률을 조정하여 최신 기울기를 더 크게 반영함
- 효과: 보폭 크기 개선
- Adam
- Momentum과 RMSProp 장점을 함께 사용
- 가장 많이 사용하는 optimizer
- 효과: 정확도와 보폭 크기 개선
정리
- 미니배치학습을 위한 데이터셋을 구성
- 딥러닝 모델인 인공신경망을 구현
- 우리가 풀고자하는 문제에 맞는 손실함수(L2, CE, BCE) 사용
- 경사하강법에 문제를 보완하기 위해 적절한 옵티마이저를 선택 (그냥 닥 Adam)
- 학습 과정
- 데이터셋을 딥러닝 모델에 넣는다
- 예측 결과에 대한 손실을 구함
- 역전파를 통해 모델 가중치의 기울기를 구하기
- 옵티마이저를 이용하여 모델 가중치를 업데이트